Retrieval-Augmented Generation (RAG) is an AI framework that enhances large language models by allowing them to access external knowledge sources before generating a response. Instead of relying solely on their pre-trained data, RAG retrieves relevant, real-time information from trusted documents or databases to produce more accurate, up-to-date, and context-aware outputs, without retraining the model.
You will get to know more about it when we will explore how does RAG works.
How Does RAG Work? Step-by-Step Guide
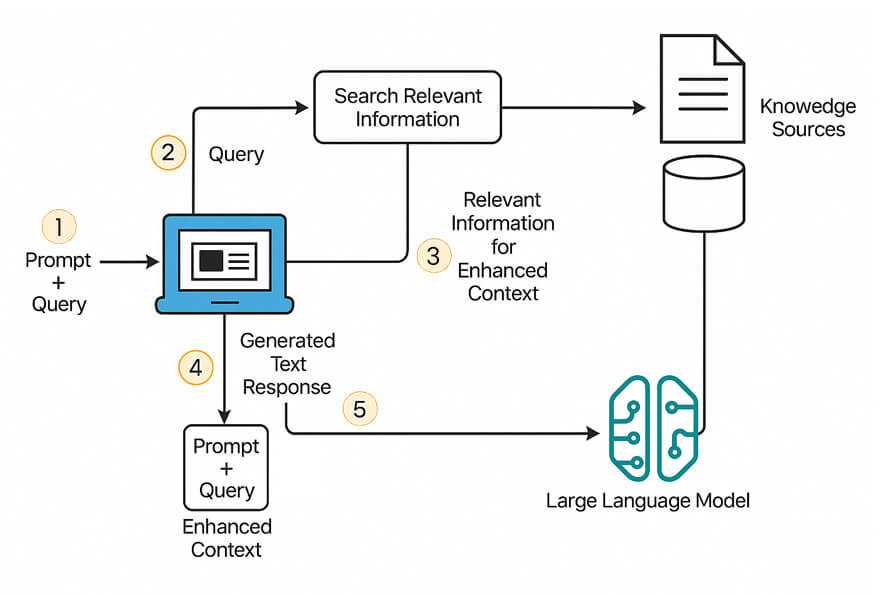
Retrieval-Augmented Generation (RAG) may sound technical, but its workflow is straightforward when broken into clear steps. Here’s how it works from start to finish:
1. Knowledge Source and Indexing
RAG systems begin by connecting to trusted knowledge sources. These can include:
Internal company documents
Research databases
API responses
Web pages or cloud-based content
Once the data is gathered, it goes through indexing so the system can search it efficiently later. This involves three key tasks:
Chunking the Content Large documents are broken into smaller pieces or “chunks” that are easier to work with.
Generating Embeddings Each chunk is transformed into a numeric representation using an embedding model. These embeddings capture the meaning of the text in vector form.
Storing in a Vector Database The embeddings are saved in a vector database or index. This allows the system to later retrieve the most relevant pieces using similarity matching.
2. The User Query
Next, a user submits a prompt—this could be a question, command, or task.
The system processes the query by:
Converting it into an embedding, using the same embedding model used during indexing.
Preparing it for a similarity comparison with the stored document chunks.
3. Retrieval of Relevant Information
This is where the system finds the best matches for the user’s query.
Using similarity search techniques such as:
Cosine similarity
Dot product
The system scans the vector database to identify the top-ranked chunks most relevant to the query.
Accuracy here is critical. Poor matches can confuse the model, while strong matches enhance understanding and output.
4. Augmentation of the Prompt
Once relevant chunks are retrieved, they’re combined with the original query to create a more detailed prompt.
This process, called prompt augmentation, gives the language model the context it needs to respond accurately.
Prompt engineering plays a big role. It’s about structuring the final input so the model makes the best use of the added knowledge.
5. Generation of the Response
Finally, the augmented prompt is passed to the LLM.
The model uses:
Its internal training
The retrieved external context
to generate a response that’s more accurate, relevant, and grounded in real-world data.
This Infographic shows how does RAG work
Key Benefits of Using Retrieval-Augmented Generation (RAG)
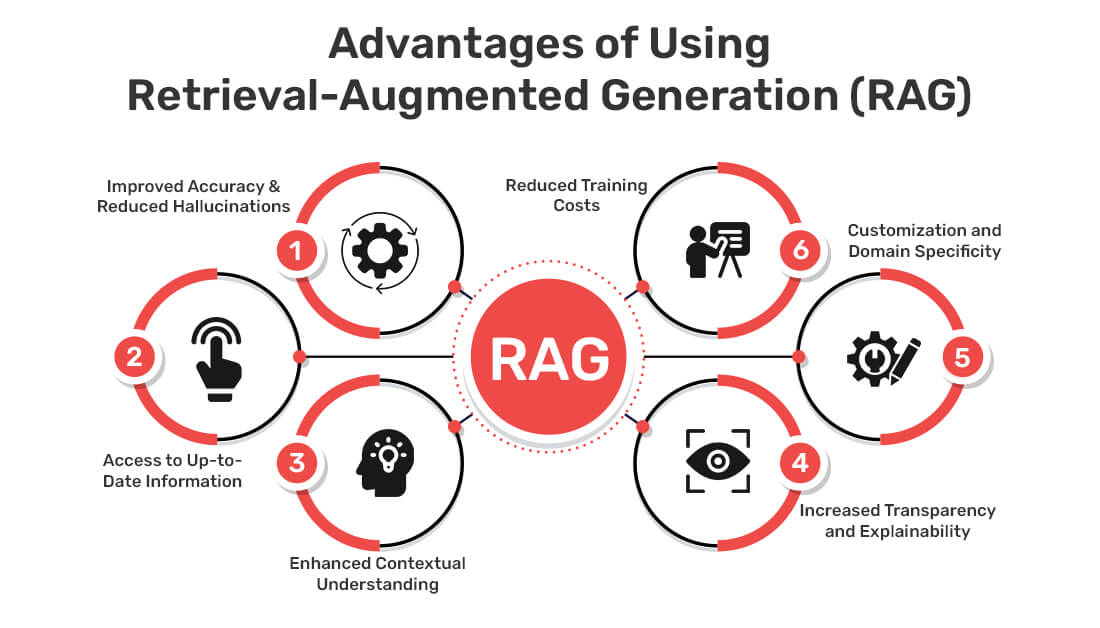
Retrieval-Augmented Generation (RAG) strengthens large language models by making them smarter, more accurate, and easier to manage. Below are the main benefits of using RAG in real-world applications:
Improved Accuracy and Reduced Hallucinations RAG improves the quality of responses coming from the model. It gives the model access to trusted data while answering. This reduces the chances of incorrect or made-up information. The model becomes more reliable and better grounded in real facts.
Access to Up-to-Date Information Language models are trained on static data. This means they can miss recent updates. RAG solves this by adding current information. It connects the model to updated sources like news, research papers, or live databases. As a result, users get more relevant and timely answers.
Enhanced Contextual Understanding RAG adds context from outside sources. This helps the model better understand what the user wants. It retrieves specific details and includes them in the prompt. That leads to more focused and helpful responses.
Increased Transparency and Explainability RAG can show where the answer came from. It links back to the source data. Users can review the original content if they need more detail. This builds trust in the system and its responses.
Customization and Domain Specificity Every business has different needs. RAG makes it easy to adapt the model for specific industries. You can use internal manuals, medical records, or product guides as data sources. No retraining is required. The model learns from the content you give it.
Reduced Training Costs
Training a model from scratch is expensive. RAG avoids that. It works with existing models and adds new knowledge without retraining. This saves time, reduces costs, and speeds up development.
Key Components and Architecture of a RAG System
A RAG system brings together different parts to retrieve information and generate accurate answers. Here’s a look at the main components that make it work.
Large Language Model (LLM) This is the part that creates the final response. It takes the user’s question and the retrieved context, then generates a natural language answer. The LLM uses its training and the new data together.
Embedding Model The embedding model turns text into numbers. These numbers are called vector embeddings. They help the system understand what the text means. Both the data and the user’s query are turned into embeddings for comparison.
Vector Database or Index This is where the system stores all the embeddings. It lets the system search through data quickly. When a user asks a question, the system finds the most similar pieces of information from this database.
Data Sources RAG works with many types of data. This can include documents, websites, PDFs, spreadsheets, internal tools, or APIs. These sources are added to the system and turned into embeddings during setup.
Retrieval Mechanism This part helps find the most relevant information. It compares the query embedding with the stored embeddings in the database. Common methods include cosine similarity or dot product. The goal is to find the closest match to the user’s question.
Prompt Engineering After retrieving the right data, the system builds a better input for the LLM. This is known as prompt engineering. It combines the original question with the retrieved context. A well-crafted prompt leads to better answers.
Real-World Use Cases and Applications of RAG
RAG systems help users interact with complex data using natural language. This makes them useful in many real-world scenarios. Below are common use cases where RAG improves both performance and experience.
Customer Support Chatbots
Many chatbots struggle to answer detailed questions about products or services. RAG connects these bots to internal company data to make AI chatbot services more efficient. This gives them the most current and accurate information. Customers get better support, and agents save time. The same setup works for personal assistants and virtual avatars, allowing them to deliver more personalized answers by using user data and past interactions.
Internal Knowledge Bases
Employees often need quick answers to company-specific questions. RAG systems can search through HR policies, onboarding guides, technical manuals, and more. Staff can find information without needing to read through large documents. This improves efficiency and helps teams work smarter.
Research and Analysis
RAG helps professionals gather insights faster. It can access and analyze internal reports, academic papers, or live web data. A financial analyst, for example, can pull market trends along with client history to build a tailored report. A doctor can use RAG to check patient records and medical guidelines at once.
Content Creation
RAG improves the quality and reliability of AI-generated content. Writers and marketers can use it to create blog posts, summaries, or articles backed by source data. Since RAG can reference real documents, the risk of false or outdated content is lower.
Question Answering Systems
RAG powers systems that need to deliver quick and reliable answers. These systems can support customer service, online help desks, or even legal advisors. Because they pull answers from trusted data, their responses are more accurate than standard AI tools.
Personalized Recommendations
RAG uses user history and real-time data to offer better suggestions. Whether on a streaming app or an online store, it can match content or products to user preferences. This keeps users more engaged and increases satisfaction.
What is the Difference Between Retrieval-Augmented Generation, Semantic Search, and Fine-Tuning?
RAG, semantic search, and fine-tuning are three distinct methods to enhance the capabilities of large language models (LLMs). Each serves a unique purpose and is suited for specific applications.
Retrieval-Augmented Generation (RAG)
RAG combines a language model with a retrieval system. When a user poses a question, RAG searches external data sources for relevant information and feeds this context into the model to generate a response. This approach allows the model to access up-to-date and domain-specific information without retraining.
Semantic Search
Semantic search focuses on understanding the meaning behind a user’s query to retrieve the most relevant documents or data points. It uses vector embeddings to match queries with content that has similar meaning, even if the exact words differ. Unlike RAG, semantic search retrieves information but does not generate new responses.
Fine-Tuning
Fine-tuning involves training an existing language model on a specific dataset to adapt it to particular tasks or domains. This process adjusts the model’s parameters, enabling it to understand specialized terminology and perform better in targeted applications. However, fine-tuning requires substantial data, computational resources, and time.
RAG vs Semantic Search vs Fine-Tuning: Summary Comparisons
Feature
Retrieval-Augmented Generation (RAG)
Semantic Search
Fine-Tuning
Main Function
Retrieves data and generates responses
Finds relevant data only
Customizes the model through extra training
Uses External Data
Yes
Yes
Not typically
Response Type
Generated natural language response
Document or snippet retrieval
Generated response based on fine-tuned behavior
Model Update Needed
No retraining required
No retraining required
Requires retraining
Best For
Providing real-time, contextual answers
Finding documents based on meaning
Specializing the model in a niche or domain
Cost & Complexity
Moderate
Low
High
Example Use Case
AI assistant accessing company documents
Search bar for internal knowledge base
Medical chatbot trained on clinical language
How Prismetric Helps You Build Powerful RAG-Based AI Solutions
Our team understands how to combine large language models with real-time data retrieval to improve accuracy, relevance, and context in every response. Whether you need an internal knowledge assistant, a smart chatbot, or a Gen AI content generation tool, Prismetric can deliver a solution tailored to your data and goals.
Here’s how we support your RAG development needs:
Custom RAG System Design We build systems that match your business logic, industry use case, and data structure—ensuring precision at every step.
End-to-End Development From connecting data sources to setting up vector databases and integrating LLMs, we handle it all.
Domain-Specific Optimization We help you fine-tune retrieval strategies and prompts based on your domain—whether it’s healthcare, finance, retail, or enterprise.
Scalable and Secure Architecture We design RAG systems that are cloud-ready, performance-optimized, and secure enough to handle sensitive business data.
Ongoing Support and Monitoring Our job doesn’t stop at deployment. We offer continuous improvement, testing, and optimization services to keep your system performing at its best.
With Prismetric as your AI development partner, you don’t just get a working RAG system—you get a future-ready AI solution that grows with your business.
Hardik Shah
As the tech-savvy Project Manager at Prismetric, his admiration for app technology is boundless though!He writes widely researched articles about the AI development, app development methodologies, codes, technical project management skills, app trends, and technical events. Inventive mobile applications and Android app trends that inspire the maximum app users magnetize him deeply to offer his readers some remarkable articles.
Get thoughtful updates on what’s new in technology and innovation
Streamline your operations and grow your business by getting the best application built


 FintechMerging latest technologies with
FintechMerging latest technologies with